どうも。くれとむです。
2023年8月11日にAWS認定Machine Learning – Specialty(MLS-C01)にスコア798で合格しました。

本記事では、MLSの試験概要と合格するための試験対策、勉強時間などをお伝えします。
これから試験を受ける方の参考になれば幸いです。
- 受験区分:MLS-C01
- 勉強期間:1ヶ月(約56時間)
- 試験対策:参考書、Udemy教材、AWS WEB問題集、AWS Blackbelt、ChatGPTなど
- IT系の保有資格:AWS認定(CPP、SAA、DVA、SOA、SAP、DOP、ANS、SCS、MLS(New!))、基本情報技術者
- 経歴:SE 3年目
- AWS使用歴:システム構成検討、環境構築を6ヶ月ほど
Contents
Machine Learning – Specialtyとは?
試験概要
AWS Certified Machine Learning – Specialty は、開発またはデータサイエンスの担当者で、AWS クラウドでの機械学習 (ML)/深層学習ワークロードの開発、アーキテクチャ設計、実行において 1 年以上の実践経験を持つ個人を対象としています。
AWS Certified Machine Learning – Specialty試験ガイドより
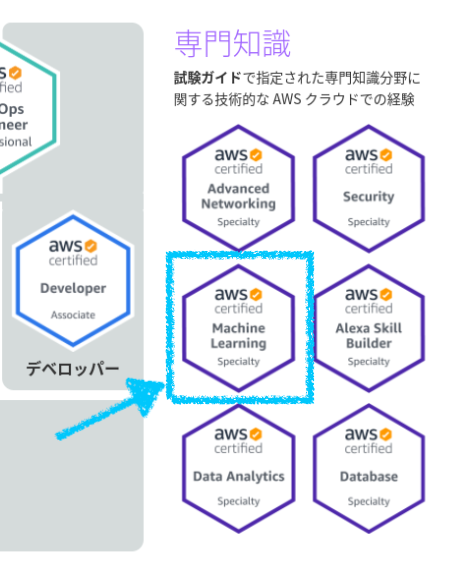
- レベル: 専門知識
- 時間: 180 分
- コスト: 40,000円(2024/4/1から)
- 形式: 選択式問題(65問)
- テスト方法: Pearson VUE を通じたテストセンターまたはオンライン監督付き試験
Machine Learning – Specialtyはその名の通り、”機械学習”に関する試験です。
AWSにおける、Amazon SageMakerやKinesis Analyticsのような機械学習が行えるサービスを中心とした問題が出題されます。

またAWS特有のサービスに加えて、一般的な機械学習の知識も問われるため、機械学習に馴染みのない方は事前に勉強しておく必要があるでしょう。
例えば一般的な機械学習の問題として、公式から以下のような例題が挙げられています。
AWS 認定機械学習 – 専門知識 AWS Certified Machine Learning – Specialty (MLS-C01) 認定試験の質問例
問題) データサイエンティストがロジスティック回帰を使用して、不正検知モデルを作成しています。モデルの正確性 は 99% ですが、不正ケースの 90% は、このモデルで検知されません。
不正ケースの検知率が確実に 10% を上回るようにするには、どうすればよいですか。
A. アンダーサンプリングを使用して、データセットを均衡化する
B. クラス確率閾値を減らす。
C. 正則化を使用して、オーバーフィッティングを減らす。
D. オーバーサンプリングを使用して、データセットを均衡化する。正解) B – クラス確率閾値を減らすと、モデルの感度が向上するので、陽性クラス (この場合は不正ケース) としてマークされるケースの数が増えます。これにより、不正を検知できる可能性が高まります。その代わり、精度が低下します。
AWS 認定機械学習 – 専門知識 AWS Certified Machine Learning – Specialty (MLS-C01) 認定試験の質問例より
例えば、以下のような機械学習における主要な用語が理解できる程度の知識は必要かと思われます。
- データセット (Dataset): 学習や評価に使用されるデータの集合。
- トレーニングデータ (Training Data): モデルを学習するために使用されるデータ。
- テストデータ (Test Data): 学習されたモデルの性能を評価するために使用されるデータ。
- 特徴量 (Feature): 入力データの変数や属性。例:家の価格を予測する場合の家の大きさや場所など。
- ターゲット/ラベル (Target/Label): 予測や分類を目指す変数。上述の家の価格の例では、実際の価格がターゲットとなる。
- 回帰 (Regression): 連続的な出力を予測するタスク。例:家の価格予測。
- 分類 (Classification): 2つ以上のクラスやカテゴリにデータを分けるタスク。例:メールがスパムか否かを判断するタスク。
- クラスタリング (Clustering): 類似性に基づいてデータをグループに分けるタスク。
- 過学習 (Overfitting): トレーニングデータに対しては非常によく適合するが、新しいデータに対してはうまく機能しないモデルの状態。
- 正則化 (Regularization): 過学習を防ぐための技法。モデルの複雑さを制限することで実現する。
- 損失関数 (Loss Function): 予測の誤差を数値化する関数。
- 勾配降下法 (Gradient Descent): 損失関数の最小化を目指して、モデルのパラメータを反復的に更新する方法。
- バッチ学習 (Batch Learning): 全てのトレーニングデータを一度に使用してモデルを学習する方法。
- オンライン学習 (Online Learning): データを小さなバッチに分けて連続的にモデルを学習する方法。
- アンサンブル学習 (Ensemble Learning): 複数のモデルを組み合わせてより良い予測を得る方法。例:ランダムフォレスト、ブースティング。
- ハイパーパラメータ (Hyperparameter): 学習前に設定する、アルゴリズムの振る舞いを決定するパラメータ。

また機械学習における主要モデルが、どのような仕組みで、どのような用途で使われるかを理解しておく必要があります。
- 線形回帰 (Linear Regression):連続値を予測するためのシンプルなモデル。
- ロジスティック回帰 (Logistic Regression):二項分類問題や多クラス分類問題に使用されるモデル。
- 決定木 (Decision Trees):分類や回帰問題に使用できる階層的な構造を持つモデル。
- ランダムフォレスト (Random Forest:複数の決定木を組み合わせて使用するアンサンブル手法。
- サポートベクターマシン (Support Vector Machines, SVM:データのクラスを分離する境界線(または多次元空間での超平面)を最適化する分類器。
- k近傍法 (k-Nearest Neighbors, k-NN):入力データの最も近いk個のトレーニングデータ点を基に予測や分類を行うシンプルなアルゴリズム。
- ニューラルネットワーク (Neural Networks):多層のノード(ニューロン)から構成されるモデル。ディープラーニングの基盤となるアルゴリズムの一つ。
- 畳み込みニューラルネットワーク (Convolutional Neural Networks, CNN):画像認識や画像処理タスクに特化したディープラーニングのモデル。
- 再帰型ニューラルネットワーク (Recurrent Neural Networks, RNN:時系列データやテキストなどのシーケンスデータを扱うためのディープラーニングのモデル。
- 主成分分析 (Principal Component Analysis, PCA:データの次元を減少させるための特徴抽出アルゴリズム。
- 勾配ブースティング (Gradient Boosting:複数の弱い学習器(たとえば浅い決定木)を組み合わせて、誤差を逐次的に修正するアンサンブル手法。
- オートエンコーダ (Autoencoders):入力データを圧縮した後に再構築するニューラルネットワーク。異常検出や次元削減に使用される。
試験範囲
AWS公式サイトのMLS試験ガイドから、ポイントを抜粋します。
AWS Certified Machine Learning – Specialty (MLS-C01) 試験ガイド
まず各分野のパーセンテージは以下のようになっています。
| 第1分野 | データエンジニアリング | 20% |
| 第2分野 | 探索的データ分析 | 24% |
| 第3分野 | モデリング | 36% |
| 第4分野 | 機械学習の実装と運用 | 20% |
受験要項としては、以下が推奨されています。
- AWS クラウドでの ML/深層学習ワークロードの開発、設計、実行における、最低 2 年の実務経験
→2年間の実務がなくても試験を受験することが可能です。 - 基本的な ML アルゴリズムの基となる考えを表現する能力
→回帰、分類、クラスタリング、強化学習、深層学習などに関する知識が必要 - 基本的なハイパーパラメータ最適化の実践経験
→学習率、エポック数、バッチサイズ、活性化関数などに関する知識が必要 - ML および深層学習フレームワークの使用経験
→Numpy、PyTorch、Tensorflow、MXNetなどに関する知識が必要 - モデルトレーニング、デプロイと運用のベストプラクティスを実行する能力
→SageMakerによるモデルトレーニングやDockerとS3からのMLモデルの呼び出しなどに関する知識が必要

この試験ガイドを見ても、AWSのサービスだけでなく、機械学習の一般的な知識が求められていることが分かりますね。
MLSの難易度は?
試験の難易度は、やや難しいと思います。
実際に受験してみて感じた難易度は、SAP=ANS > MLS > DOP > DAS > SCS > PAS > DBS > SOA > SAA > DVA > CLFという感じでした。
機械学習に関する一般的な知識も問われることも難易度が高いと感じたひとつの理由です。
僕の場合は、機械学習に関する勉強をしたことがなかったので、UdemyやYoutubeで機械学習の勉強から始めました。
また他の方の合格記を読んでいると、以下のような意見もちらほらありました。

データ分析に関する知識も問われるので、AWS Certified Data Analytics – Specialtyを先に受験した方がいいよ。

G検定を先に受験して、機械学習の知識を蓄えてからMLSを受験したよ。
僕自身はMachine Learning – Specialtyに合格してから、Data Analytics – Specialtyを受験しましたが、確かにKinesisやGlueなど両試験に共通して問われるサービスも多々ありました。
Machine Learning – Specialtyの方が難易度も高いので、Data Analytics – Specialtyを先に受験しておくのもひとつの手かなと思います!
以下の記事にて、Data Analytics – Specialtyの合格記も記載しておりますので、ぜひチェックしてみてください。

MLSの勉強時間は?
MLSの学習に使った時間は、約 56時間 でした。
スマホアプリで勉強時間を測っていました。

勉強時間配分に関しては大体以下の感じです。
僕自身は、特にUdemy講座受講に多くの時間を費やしました。
| 学習教材 | 勉強時間の配分 |
| Udemy(講義) | 33時間 |
| Udemy(問題集) | 3時間 |
| Web問題集 | 13時間 |
| 参考書 | 3時間 |
| メモ帳整理&確認 | 1時間 |
| BlackBelt、Youtube | 3時間 |
| 合計 | 56時間 |
MLSの勉強方法
- Udemy教材を活用
- Tech StockのWEB問題集を解く
- YoutubeとBlackBelt資料を活用
- MLSの参考書を読む
- ChatGPTを活用
Udemy教材を活用
MLSの学習にあたって、Udemyで以下の教材を活用しました。
Udemyは月に2,3度セールがあり、その時期は2,000円ほどで購入可能なので、セールのタイミングを狙って購入することをオススメします。

機械学習に関する一般的な知識(回帰、分類、クラスタリング、強化学習、深層学習など)、およびPythonとRを用いたデータ処理とモデル実装を学ぶことができる教材です。
受講者数は、世界中で900,000 人以上だそうです。

オススメ度は星5つです(★★★★★)
僕自身、試験勉強の最初にこの教材を使って勉強し、機械学習の基礎知識を身につけることができました。
英語教材というのが難点ですが、日本語字幕(自動)をつけることができます。
最近の自動字幕は精度が高いので、字幕でも十分に学習を進めることができるでしょう。

オススメ度は星5つ中3つです(★★★☆☆)
MLSで出題される各AWSサービスの概要を体系的に学ぶことができる講座です。
こちらの教材に関しては、試験対象のAWSサービスを網羅できるのが良い点です。
しかしスライドの内容を読み上げているだけの内容も多く感じました。
英語教材(日本語字幕あり[自動])ということもあり、講師が説明している内容が理解できないことも多々ありました。
ChatGPTと併用して、教材で出てきた用語を調べつつ知識を身に付けていくという勉強方法がオススメです!
MLSは模擬試験問題も他の試験より多かったです。
以下の模擬問題集をUdemyにて実施しました。
なお模擬問題集に関しては、Chromeの日本語翻訳機能を使うと良いでしょう。
Udemyの模擬問題よりも前に、Tech StockのWeb問題集を先に勉強して、余裕があれば実施するのがオススメです。
模擬問題の教材はいくつかありますが、教材の購入費用がかさむのは嫌だと思いますので、自身の理解度を見つつ、もっと問題を解きたいと思う方は活用してみてください。
模擬問題が140問収録されています。
問題の質も良く、解説も丁寧です。
僕が解いた模擬問題の中では一番オススメです!

模擬問題が75問収録されています。
こちらの教材は問題自体は良いのですが、解説がやや不親切だと感じました。
解説よりも模擬問題を解くこと自体を重視したい方には良いと思います。

模擬問題が120問収録されています。難易度はやや易しめでした。
なおUdemyのシステム上、一つのセクションの問題を解き終わるまで答え合わせができないため、本番形式の65問ごとに区切られている場合、全て解くのが億劫だと感じることがあります。
その点で、この教材は模擬問題集のセクションが20問ごとに分かれているので、細かいタイミングで答え合わせができるのが良い点だと感じました。

- 機械学習の基礎知識を学べる教材がオススメ
- 英語の模擬問題集は、Chromeで日本語翻訳して解くと良い
- セール中に購入すれば、2,000円ほどで購入可能
Tech StockのWEB問題集を解く
TechStock|AWS WEB問題集で学習しよう
MLSの模擬問題は、210問以上解くことができます。

有料ですが、問題数が多く問題自体の質と解説のクオリティも高いため、合格に向けた事前学習には欠かせないと思います。
間違えた問題のみ表示する機能もあるので、効率的に学習することが可能です。
僕の場合は、まず問題を2周してから、3周目は間違えた問題のみ表示して、大方9割くらい解けるようになってから試験に臨むようにしています。
MLSを含めた専門知識の問題はプロフェッショナルプランに加入することで解くことができます。
4,580円(税込)で90日間の利用が可能です(2023.8.18時点の料金)。
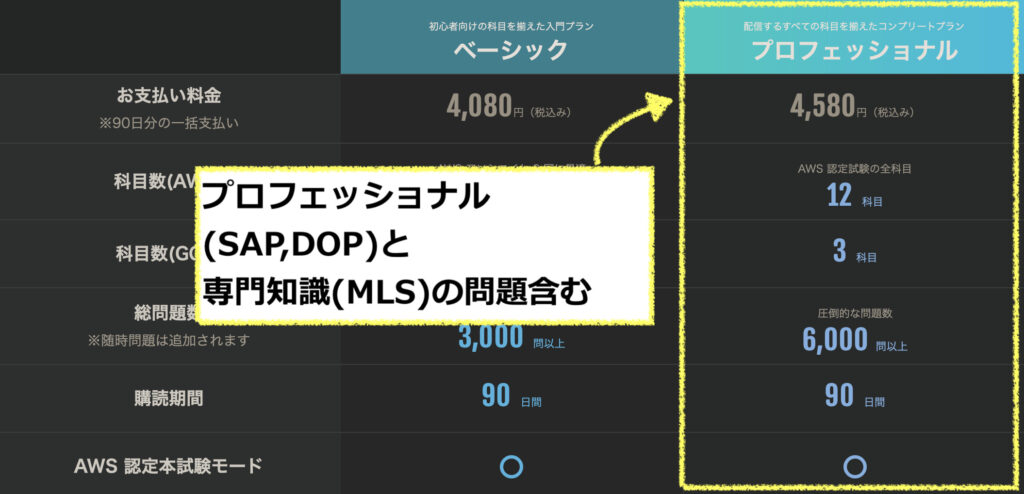
MLSは他のAWS試験に比べると問題数があまり多くないので、物足りないという方は先ほど記載したUdemyの模擬問題集を活用するのがオススメです。
- MLSの模擬問題は210問以上
- MLSの問題を解くためには、プロフェッショナルプラン加入が必要
YoutubeとBlackBelt資料を活用
Youtubeに投稿されているBlackBeltの動画を見ることもおすすめします。
各サービスごとに大体50分くらい動画で要点が分かりやすくまとめられています。
(通常速度だと時間がかかるので、1.5倍速にして動画視聴していました。)
- Amazon SageMaker Training で機械学習のモデル開発を楽にする【ML-Dark-01】
- AWS Glue【AWS Black Belt】
- 【AWS Black Belt Online Seminar】AWS Glue DataBrew
- 【AWS Black Belt Online Seminar】Amazon EMR
- 実践 Amazon Sagemaker – 全体像からユースケースまで
BlackBeltの動画に使われている資料は以下のリンク先から確認することができるので、
こちらの資料を使って苦手分野を重点的に確認するのも良いでしょう。
AWS サービス別資料

BlackBeltに加えて、一般的な機械学習の勉強には、「
スタビジ【誰でもAIデータサイエンス】byウマたん」というYoutubeチャンネルが非常にお勧めです。
機械学習に関する動画が数分程度で分かりやすいイラストともにまとめられています。
ChatGPTを活用する

もはや全ての試験に共通する勉強方法ですが、ChatGPTに分からないことを聞くという勉強方法が非常にお勧めです。
2021年までの情報しかないのと誤った情報が返ってくることがあるのが難点ですが、Google検索するのが難しい口語ベースの質問にも的確に返答してくれるのがとても助かります。
以下のように、聞いた内容に対して的確にかつ分かりやすく答えてくれます。

回帰分類とバイナリ分類の違いは?
機械学習において「回帰」、「分類」、そして「バイナリ分類」は、タスクの種類を表す重要な用語です。それぞれのタスクの違いは以下の通りです:
- 回帰:回帰は、目的変数(または応答変数)が連続値を取るタスクを指します。つまり、数値の範囲全体にわたる予測を行います。例えば、家の価格予測や株価予測などが回帰タスクに該当します。使用されるアルゴリズムには線形回帰、決定木回帰、サポートベクター回帰などがあります。
- 分類:分類は、目的変数がカテゴリ(またはクラス)を取るタスクを指します。つまり、予測される出力はカテゴリに属します。例えば、メールがスパムであるか否かの予測や、画像に犬が含まれているか否かの予測などが分類タスクに該当します。使用されるアルゴリズムにはロジスティック回帰、決定木分類、サポートベクター分類、ニューラルネットワークなどがあります。
- バイナリ分類:バイナリ分類は分類の一種で、目的変数が2つのカテゴリのみを取るタスクを指します。つまり、予測される出力は2つのカテゴリのうち1つになります。先ほどのメールがスパムであるか否かの予測はバイナリ分類の一例です。

たまに嘘の情報を教えてくることもありますが、自身の知りたいことを文章ベースで調べることができるのは、非常に助かります。
正直、ChatGPTなしの勉強はもう考えられないくらい重宝していました。
チューリングマシンを発明したアラン・チューリングは、1950年の論文「Computing Machinery and Intelligence」でチューリングテストを提唱しました。
人間の審査員がコンピュータとのテキストベースの対話を行い、対話の相手が人間かコンピュータかを判断するというものです。
その中でチューリングは、「もし審査員がコンピュータを人間と見分けることができなければ、そのコンピュータは「知的行動」を持つと考えられる」と提唱しました。


様々な文章に応じて、臨機応変な対応をしてくれるChatGPTでは、「中の人が文章を作成しているのでは?」と疑うくらいの性能をしています。
チューリングの定義における「知的行動」と言えますね。
以下の記事で、アレクサとChatGPTを連携した内容を記載しています。
本当に人と会話しているくらいの内容が返ってくるので、楽しかったです。
ぜひチェックしてみてください。

まとめ
MLSは機械学習の一般的な知識も求められる試験であったため、覚えることが多く大変でした。
ただ機械学習はIT技術者であれば身につけておいて損はないので、AWS認定試験を通じて勉強できてよかったと感じています。
AWSにおける機械学習関連サービス(SageMakerやGlueなど)は、まだ実際に使ったことはないので、今後実務でも経験を積みたいと思っているところです。
機械学習は膨大なデータを必要とするので、個人では実装しづらいなと思ったりします。
機械学習を柔軟に扱えるようになれば、楽しいだろうな〜!
なのでMLS資格取得が機械学習関係の業務に携わるきっかけになればと思っています。
最後まで読んでいただきありがとうございました。
本記事がこれからMLSを受験する人にとって、少しでも参考になれば幸いです。
ではでは。