「AIコパイロットを自社のWebアプリに組み込みたいが、バックエンドを大きく変える余裕はない」——そんな要望に応える選択肢のひとつが Page Agent です。
ブラウザ内で完結するGUIエージェントであり、scriptタグ1行から試せる手軽さを持ちながら、BYOK(Bring Your Own Key)設計によって本番運用にも対応できる拡張性を備えています。

本記事では公式ドキュメントをもとに、仕組み・導入手順・運用上の注意点を順を追って解説します。
Page Agentとは?
Page Agentは、ブラウザページの中だけで動作するGUIエージェントライブラリです。
公式READMEには次の一文があります。
ブラウザ拡張機能、Python、ヘッドレスブラウザは不要です。ページ内JavaScriptのみで完結し、すべてお使いのウェブページ内で処理されます。
(出典:Page Agent README)

この設計思想が示す通り、Python環境もヘッドレスブラウザも不要です。
ページにスクリプトを1行挿入するだけで、自然言語によるUI操作のプロトタイプが動き始めます。
技術的な核心は「スクリーンショットや視覚認識に頼らない」点にあります。
PageControllerがDOMをテキスト化(dehydration)し、その情報をLLMに渡すことで「どの要素をどう操作するか」を決定します。
LLMが返したツール呼び出しに従い、インデックス化された要素を確定的に操作する——この一連の流れがブラウザ内で完結します。
裏を返せば、画像・Canvas要素を主体とするUIや、視覚的な座標指定が必要な操作には対応していません(Known Limitations参照)。

導入前にこの制約を把握しておくことが、無駄な工数を省く第一歩だね。
導入方法は大きく2通りあります。
評価目的ならデモCDNのscriptタグ1行、プロダクト組み込みなら npm install page-agent です(詳細はクイックスタートセクションで解説します)。
主な特徴とユースケース
Page Agentが持つ主な特徴を整理すると、次の3点に集約されます。
- テキストベースのDOM操作:視覚認識なしにテキスト化したDOMだけで操作を完結させるため、動作が軽量かつ再現性が高い
- BYOK設計:OpenAI・Anthropicなど任意のLLMプロバイダをAPIキーごと持ち込める。
プロバイダへの依存を排除し、コスト最適化もしやすい - human-in-the-loop対応のUIパネル:組み込みのパネルUIでユーザーが操作を確認・承認しながら進められるため、誤操作リスクを軽減できる
AIコパイロットってどんな場面で使うの?具体例が知りたい。
サンプルユースケース
- SaaS AI Copilot:管理画面やダッシュボードに数行のコードを追加するだけで、自然言語によるユーザー操作アシストを実現できます。バックエンドに手を入れずにPoCを始められる点が最大の利点です。
- Smart Form Filling:複数フィールドへの入力を1文の自然言語で完結させるワークフロー。公式READMEのデモでは「20回のクリック操作を1文に変換する」例が示されています。入力フォームが多い業務システムとの相性が良い用途です。
- アクセシビリティ支援:音声入力や自然言語コマンドを受け取ってページ操作を代行することで、スクリーンリーダーの補助や運動機能に制約のあるユーザーへの支援に活用できます。ただし、音声認識部分は別途実装が必要であり、Page Agent単体で完結するわけではありません。
- マルチページ拡張:Chrome拡張との組み合わせにより、タブをまたいだ複数ページの自動化も可能です。ただしこれはオプショナルな構成であり、導入の複雑さが増します(拡張機能ドキュメント参照)。
なお、公式CHANGELOGによると、バージョン更新を経て maxSteps のデフォルト値が20から40に引き上げられました。
これにより、より複雑な多ステップタスクを途中で打ち切らずに実行できるようになっています(出典:CHANGELOG.md)。
一方で、画像・Canvas要素が主体のUI、複雑なドラッグ操作、視覚的な座標指定が必要な操作には不向きです。
「自社のUIはどちらに近いか」を事前に判断しておくと、導入効果の見積もりに役立ちます。
アーキテクチャと主要コンポーネントの仕組み
導入可否を判断するには、内部構造を把握しておくことが欠かせません。
Page Agentは次の4つの主要パッケージで構成されています。
page-agent:UIパネル込みのメインパッケージ。手軽に試すときはこれ1つで十分@page-agent/core:UIを持たないheadlessコア。既存のUIに組み込む場合はこちらを使う@page-agent/llms:LLMプロバイダとの通信を担うクライアント層@page-agent/page-controller:実際のDOM操作を実行する層
UIが不要であれば @page-agent/core だけを取り込むことができ、既存のデザインシステムを壊さずに機能を追加できます。
DOM抽出 → 脱水(dehydration)→ LLM → ツール呼び出しの流れ
処理の流れは次の4段階です。
- DOM抽出・インデックス化:PageControllerが現在のページDOMをスキャンし、操作可能な要素に連番インデックスを付与します。
- 脱水(dehydration):スタイルや不要な属性を除いたテキスト表現に変換し、LLMへのコンテキストを最小化します。
- LLMへの送信と応答取得:脱水済みDOMとユーザーの自然言語指示をまとめてLLMに送信し、「どの要素をどう操作するか」という応答(ツール呼び出し)を受け取ります。
- PageControllerによる実行:受け取ったインデックス番号を使ってDOM要素を確定的に特定し、クリック・入力などを実行します。
また、バージョン1.2.0からは「Observe Phase」が追加され、各ステップ実行前にエージェントが状況を観察するフェーズが挿入されました。
これによりエージェントの安定性と精度が向上しています。
BYOK(Bring Your Own Key)とテストAPIの位置づけ
Page AgentはBYOKを前提とした設計です。new PageAgent({ model, baseURL, apiKey }) の形で任意のLLMプロバイダを指定でき、すべての通信はユーザーが設定したエンドポイントに対して行われます。
ライブラリ自体がデータを収集・送信する仕組みにはなっていません。
ただし、評価目的で用意されているテストAPIには明確な制約があります。
公式の docs/terms-and-privacy.md では以下が明記されています(出典:terms-and-privacy.md)。
- テストAPIは技術評価のみを目的としている
- 個人情報(PII)の送信は禁止されている
- 処理はAlibaba Cloudを経由する場合がある
要するに、テストAPIはR&D用途に限定し、本番運用では必ず自前のAPIキーに切り替えることが公式の推奨です。
この原則はセキュリティ設計の起点として捉えてください。
実際に使ってみた
まず動かすことで理解が深まります。
ここでは「デモCDNで1行試す」「npmでローカル実装する」の2段階で手順を示します。
1行で試す(デモCDN)
- 任意の静的HTMLページ、または開発中のSPAに次のscriptタグを挿入します。
<script src="https://cdn.jsdelivr.net/npm/page-agent@1.5.6/dist/iife/page-agent.demo.js" crossorigin="true"></script>- ページをブラウザで開きます。
- 画面上に表示されるパネルUIから、自然言語の指示を入力して実行します。
- 指示に沿って画面が動くことを確認します。
htmlファイル一つで試すことができます。
以下のようなコードで挙動を試しました。
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Page Agent Interactive Demo</title>
<style>
body {
font-family: sans-serif;
background-color: #f0f2f5;
display: flex;
flex-direction: column;
align-items: center;
padding: 40px;
}
.demo-card {
background: white;
padding: 30px;
border-radius: 12px;
box-shadow: 0 4px 20px rgba(0,0,0,0.08);
max-width: 500px;
width: 100%;
}
.status-badge {
display: inline-block;
padding: 4px 12px;
border-radius: 20px;
font-size: 0.85rem;
font-weight: bold;
margin-bottom: 15px;
}
.ready { background: #d4edda; color: #155724; border: 1px solid #c3e6cb; }
.form-group { margin-bottom: 15px; }
label { display: block; margin-bottom: 5px; font-weight: bold; }
input { width: 100%; padding: 8px; border: 1px solid #ddd; border-radius: 4px; box-sizing: border-box; }
button {
background: #4A90E2;
color: white;
border: none;
padding: 10px 20px;
border-radius: 6px;
cursor: pointer;
transition: background 0.3s;
}
button:hover { background: #357ABD; }
#action-log {
margin-top: 20px;
background: #333;
color: #00ff00;
padding: 15px;
border-radius: 6px;
font-family: monospace;
font-size: 0.8rem;
height: 100px;
overflow-y: auto;
}
</style>
</head>
<body>
<div class="demo-card">
<div id="loadStatus" class="status-badge">Checking Page Agent...</div>
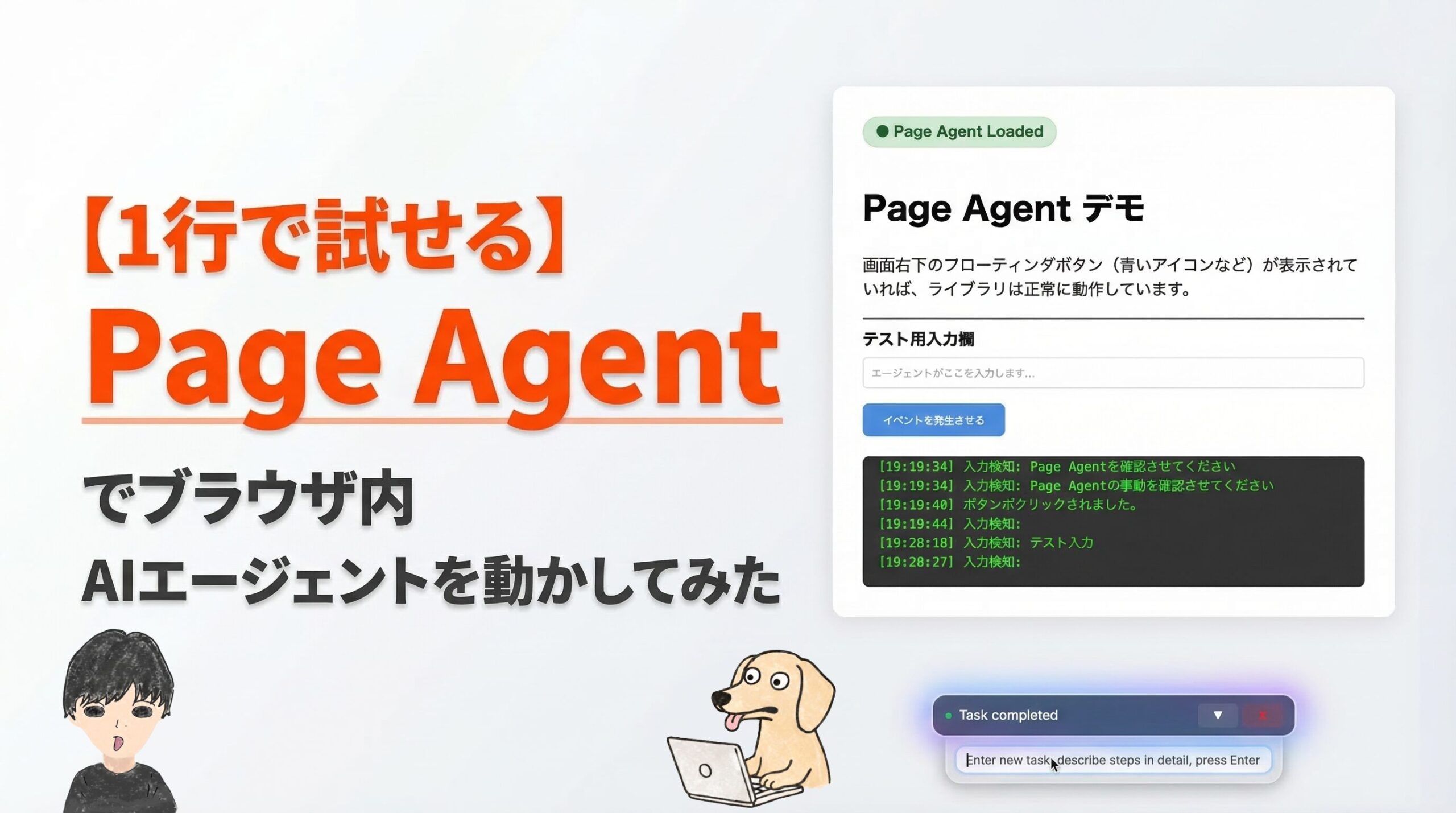
<h1>Page Agent デモ</h1>
<p>画面右下のフローティングUIが表示されていれば、ライブラリは正常に動作しています。</p>
<hr>
<div class="form-group">
<label for="username">テスト用入力欄</label>
<input type="text" id="username" placeholder="エージェントがここを入力します...">
</div>
<button id="demoBtn">イベントを発生させる</button>
<div id="action-log">
> ログ: 待機中...
</div>
</div>
<script>
function addLog(msg) {
const logArea = document.getElementById('action-log');
const time = new Date().toLocaleTimeString();
logArea.innerHTML += `<div>[${time}] ${msg}</div>`;
logArea.scrollTop = logArea.scrollHeight;
}
const statusBadge = document.getElementById('loadStatus');
document.getElementById('demoBtn').addEventListener('click', () => {
addLog("ボタンがクリックされました。");
const btn = document.getElementById('demoBtn');
btn.style.transform = "scale(0.95)";
setTimeout(() => btn.style.transform = "scale(1)", 100);
});
document.getElementById('username').addEventListener('input', (e) => {
addLog(`入力検知: ${e.target.value}`);
});
</script>
<script
src="https://cdn.jsdelivr.net/npm/page-agent@1.5.6/dist/iife/page-agent.demo.js"
crossorigin="true">
</script>
<script>
if (typeof PageAgent !== 'undefined') {
statusBadge.innerText = "● Page Agent Loaded";
statusBadge.classList.add('ready');
addLog("Page Agent スクリプトを検出しました。");
} else {
statusBadge.innerText = "● Page Agent Not Detected";
addLog("Page Agent が見つかりませんでした。");
}
</script>
</body>
</html>開発者タブのConsoleタブを開くと、以下のようなログが出ていることも確認できます。
🧠 Thinking...
page-agent.demo.js:198 MacroTool input {evaluation_previous_goal: 'This is the first step, no previous action to eval… loaded successfully with an input field visible.', memory: "Page loaded successfully. Found a text input field…here's also a button (index 2) to trigger events.", next_goal: 'Input some text into the input field at index 1 as requested by the user.', action: {…}}
page-agent.demo.js:199 ✅: This is the first step, no previous action to evaluate. The page has loaded successfully with an input field visible.
💾: Page loaded successfully. Found a text input field (index 1) with placeholder text indicating the agent should input here. There's also a button (index 2) to trigger events.
🎯: Input some text into the input field at index 1 as requested by the user.デモCDNはテスト用LLMに接続されます。
パスワード・氏名・メールアドレスなどの個人情報は絶対に入力しないでください。
npmで使う基本サンプル(PageAgentインスタンス作成 → execute)
- プロジェクトにパッケージをインストールします。
npm install page-agent- Vite/Reactなどのフロントエンド環境でimportし、インスタンスを作成します。
import { PageAgent } from 'page-agent';
const agent = new PageAgent({
model: 'gpt-4o-mini', // 使用するモデル名(BYOK設定)
apiKey: process.env.MY_API_KEY, // 自前のAPIキー
baseURL: 'https://api.your-llm-provider.example', // LLMエンドポイント
language: 'ja', // UIパネルの表示言語(オプション)
});
await agent.execute('Click the login button');
- 実行します
今回は簡単なNext.jsのアプリを作って、動作を確認してみました。
以下が実際に動作してる様子です。

沖縄のリゾート地を探して。という依頼に対してエージェントが自動でブラウザを操作していることが確認できます。
ここで使用しているテストアプリは以下のGithubに挙げているので、興味のある人は自身で動かしてみてください。
https://github.com/kuretom-blog/page-agent-demo
APIキーに関する注意事項
このデモアプリでは、page-agentがブラウザ上でDOMを直接操作する仕組みのため、APIキーをフロントエンド(`NEXT_PUBLIC_` 環境変数)で使用しています。NEXT_PUBLIC_プレフィックスの環境変数はビルド時にクライアント側のJavaScriptバンドルに埋め込まれるため、デプロイして公開した場合、ブラウザの開発者ツールからAPIキーが閲覧可能になります。
必ずローカル環境でのみ使用するようにしてください。
プライバシーとテストAPIの利用上の注意
改めて整理すると、テストAPIと自前のAPIキー(BYOK)では利用条件が大きく異なります。
| 項目 | テストAPI | BYOK(自前のAPIキー) |
|---|---|---|
| 用途 | 技術評価・R&Dのみ | PoC〜本番運用 |
| PII送信 | 禁止 | プロバイダのポリシーに依存 |
| データ経路 | Alibaba Cloud経由の場合あり | 指定したエンドポイントに直送 |
| コスト管理 | ユーザーによる管理不可 | 自社で管理可能 |
本番運用に移行する際は、テストAPIから自社のAPIキーへの切り替えを必ずロードマップに含めてください。
加えて、LLMへ送信するDOMコンテンツに機密情報が混入しないよう、フィルタリング層の実装も検討する価値があります。
導入を検討する際にチェックすべきポイント
以下のチェックリストはPoC開始前の判断を素早く行うために用意しました。
「すべてOK」でなくても導入を排除する必要はありませんが、NOが多い場合は代替アーキテクチャの検討を並行させることを推奨します。
このチェックリストで「合う/合わない」がすぐわかるね。
- 対象アプリはSPAか? Page AgentはSPAでの動作安定性が高い。サーバーサイドレンダリング主体のページでは動作確認が追加で必要になる
- UIに画像やCanvasが多く含まれるか? 視覚認識は非対応のため、画像主体のUIへの適用は困難
- ページ上に個人情報(PII)が表示されるか? テストAPIでは絶対に扱わないこと。本番移行時もデータフィルタリングの設計が必要
- BYOKで運用できる体制があるか? LLMプロバイダの選定、APIコストの試算、可用性の確認を済ませておく
- 必要なDOM操作(hover・dragなど)はサポート範囲内か? 公式READMEのKnown Limitationsで現時点の対応範囲を確認する
- カスタムツールを実装する開発リソースを確保できるか? 標準機能だけで要件を満たせない場合は、拡張実装の工数を見積もりに含める
「導入は容易だが、用途が合わなければ価値は出ない」というのが正直な評価です。
早い段階でこのチェックを済ませることが、PoC設計の無駄を省く近道になります。
まとめ
Page Agentは、ブラウザ内で完結するテキストベースのGUIエージェントです。
scriptタグ1行からPoCを始められる手軽さと、BYOKによる柔軟なLLM選択が最大の強みです。
SPA向けの自然言語操作やスマートフォーム、アクセシビリティ支援といったユースケースにはうまくはまる一方、画像・Canvas主体のUIや視覚座標依存の操作は現時点では対応外という点は把握しておく必要があります。
実践的な進め方としては、「デモCDNで動作確認 → 観察ポイントを記録 → 自前のAPIキーに切り替えてPoC → チェックリストで本番移行を判断」というステップが現実的です。
テストAPIはあくまでR&D用途に限定し、PIIが含まれる環境では使わないという原則を忘れずに。
参考リンク:






















本当に1行で動くの?試してみたい。